Open the texts after downloading and unpack / extract them from your native file manager, e. g. Windows File Explorer. Choose↘� meta-ltext for learner texts (L2 texts) with metadata or↘ meta_ltext_THs for L2 texts with target hypothesis.


MERLIN is an error-annotated written learner corpus for German, Italian and Czech. It was created within the MERLIN project (2012-2014). The texts in MERLIN were taken from standardized language tests and are methodologically precisely related to the Common European Framework of Reference for Languages (Council of Europe 2001, 2020). This platform makes all corpus texts available with their ratings. It shows possible usage scenarios, in the teaching practice as well as in research, and informs about the structure and the design of the corpus and of the annotations. Users can search the corpus with the help of the integrated web-based search engine ANNIS.
You can download the whole corpus (2.286 texts) in the following file formats:
In addition, the following corpus-related overviews are available:
All MERLIN data and ressources are freely accesible under a Creative Commons licence (CC BY-SA 4.0). They are part of the CLARIN infrastructure (European Research Infrastructure for Language Resources and Technology). Download the whole corpus from the Eurac Research CLARIN Centre Repository.
The MERLIN texts are TXT-files that you can open in a standard text editor. Descriptive file names help you easily filter the files by metadata. In addition, you can use the ANNIS search tool to sort texts and display them in the document browser.
 Open texts with the file manager
Open texts with the file managerOpen the texts after downloading and unpack / extract them from your native file manager, e. g. Windows File Explorer. Choose↘� meta-ltext for learner texts (L2 texts) with metadata or↘ meta_ltext_THs for L2 texts with target hypothesis.
Filter texts with the file managerUse the search box of your native file manager, e. g. in the Windows File Explorer (you can find it to the right of the address bar) to filter the file list for the following features (metadata):
For example, to find all texts with the overall CEFR rating B1 written by learners with Russian as their mother tongue, enter B1 Russian.
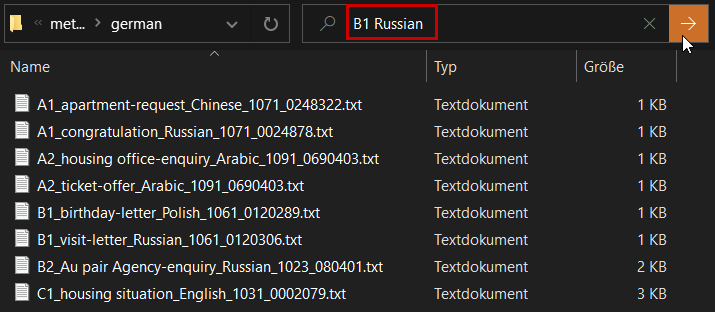
The following L1 occur in the corpus: Arabic, Czech, English, Chinese, French, German, Hungarian, Italian, Polish, Portuguese, Russian, Slovak, Spanish, Turkish.
On MERLIN Corpus you will find an overview of all tasks including the abbreviations we used in the file names.
Open texts in ANNISOpen the ANNIS search interface, go to Corpus List and select the corpus you want to display (i. e. the target language). Click on the↘ document icon [1]. In the field to the right, the list view of all MERLIN texts of the chosen language opens up. Click on ↘ Full text [2] next to a text to open it and on "i" [3] to display the assigned metadata.

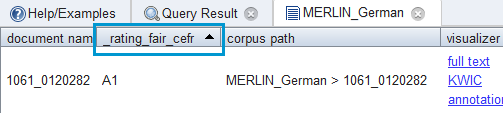
Sort texts in ANNISSelect a corpus (according to the target language) in the ANNIS search interface↘ Corpus List and click on the ↘ document icon. In the field to the right, a list view of all MERLIN texts of the chosen language opens up.
By clicking on↘ _rating_fair_cefr you can quickly sort the texts according to the CEFR level (overall rating).
If you start a search for learner language features directly in ANNIS, you can also filter texts by metadata such as the learner's L1, age or the assigned task. More on this in the next section.
You can search the MERLIN Corpus for lexcial, grammatical and other features as well as for words, lemmas, or tagged parts of speech. By doing so, you will obtain examples for learner language (L2) in context. To provide the search functionality, the MERLIN platform uses the visualization and search architecture of ANNIS, which allows to display multi-layer annotations as those of the MERLIN corpus.
Using the metadata, you can restrict queries to a specific sub-corpus, for example:
 The ANNIS User Guide offers a thorough introduction to using the ANNIS interface. You can also refer to the ANNIS help section under↘ Help/Tutorial. For explanations on the annotation layers please go to Search and help.
The ANNIS User Guide offers a thorough introduction to using the ANNIS interface. You can also refer to the ANNIS help section under↘ Help/Tutorial. For explanations on the annotation layers please go to Search and help.

